
![]()


This repository is the engine behind NAM.
It provides an include-only CMake consumer module that:
- reads
.dvcmanifests from a local manifest checkout - resolves payloads from the configured remote source into one shared local object store
- materializes normal files into build trees through
hardlink,symlink, orcopy - keeps the consumer build graph on public
CMake ExternalDataAPIs
The repository also carries the smoke consumer, documentation, vendored
ExternalData patch, and CI needed to keep that flow stable.
The module itself is not meant to be Nabla-only. Other projects can vendor
nam.cmake, keep their own .dvc-based manifest repository, publish payloads
through GitHub Release assets, and reuse the same consumer-side
materialization model without changing call sites.
Current scope is intentionally narrow. For now the only supported remote
payload backend is GitHub Release assets, and no additional backends are
planned in the near term.
For a minimal consumer example, see smoke/CMakeLists.txt.
The current Nabla examples layout at:
looks harmless because it is "just for examples", but it already creates real operational problems. Large binary payloads inside ordinary Git workflows slow down normal source-control operations, make maintenance heavier, work against setups such as Git worktrees, and couple code history to binary churn.
The core argument is simple. Source control should keep code and small reviewable metadata. Heavy payloads should stay outside normal Git history.
The intended direction is:
- manifests and references in Git
- payloads outside Git history
- backend-agnostic consumers
- one shared local object store per user
- normal local files materialized into build trees for examples and tests
- shared blob reuse across many build directories, many checkouts, and even many independent repositories
At a high level this follows the same pattern used by mature package and artifact ecosystems:
- manifest plus URL plus checksum in
winget - formula or cask plus bottle URL plus checksum in
Homebrew binaryTarget(url:, checksum:)inSwiftPM- content-addressed external test data in
CMake ExternalData, used by projects such asVTK
The same consumer module is also meant to stay reusable beyond Nabla itself.
The default first-party registry is
Nabla-Asset-Manifests,
but consumers can point the module at a different manifest checkout and a
different GitHub Release channel without changing the build-graph model.
Checking large binary files into a source repository (Git or otherwise) is a bad idea because repository size quickly becomes unreasonable. Even if the instantaneous working tree stays manageable, preserving repository integrity requires all binary files in the entire project history, which given the typically poor compression of binary diffs, implies that the repository size will become impractically large. Some people recommend checking binaries into different repositories or even not versioning them at all, but these are not satisfying solutions for most workflows.
Large repositories can slow down fetch operations and increase clone times for developers and CI.
or from the same page:
Store programmatically generated files outside of Git, such as in object storage.
DVC:
Store them in your cloud storage but keep their version info in your Git repo.
Git LFS is better than checking large blobs directly into normal Git history, but it is still not the model we want to optimize around here.
The strongest reasons are:
- it stays Git-centric instead of backend-agnostic
- it couples asset transport to hosting policy and billing
- it complicates long-term migration and reversibility
Gregory Szorc, former technical steward of the Firefox build system at Mozilla and maintainer of Firefox version control infrastructure. Quote source: Why you shouldn't use Git LFS:
If you adopt LFS today, you are committing to a) running an LFS server forever b) incurring a history rewrite in the future in order to remove LFS from your repo, or c) ceasing to provide an LFS server and locking out people from using older Git commits.
So adoption of Git LFS is a one way door that can't be easily reversed.
Operational failure modes are documented very explicitly:
from GitHub LFS billing and quota behavior:
Git LFS support is disabled on your account until the next month.
or from GitHub LFS objects in archives:
Every download of those archives will count towards bandwidth usage.
or from GitLab storage quota behavior:
When a project’s repository and LFS exceed the limit, the project is set to a read-only state and some actions become restricted.
or from Bitbucket Cloud current limitations for Git LFS:
Once any user pushes the first LFS file to the repo, then transferring of that repo is disabled.
VTK:
VTK uses the ExternalData CMake module to handle the data management for its test suite. Test data is only downloaded when a test which requires it is enabled and it is cached so that every build does not need to redownload the same data.
CMake ExternalData latest documentation:
manage data files stored outside source tree
From the same documentation:
Fetch them at build time from arbitrary local and remote content-addressed locations.
Kitware on CMake ExternalData:
The separate repository requires extra work for users to checkout and developers to maintain. Furthermore, the data repository still grows large over time.
This is the exact consumer model we want:
- a shared local object store
- reuse across many build directories and worktrees
- reuse across many independent repositories too
- normal local files materialized into build trees via symlinks, hardlinks, or copies
- no requirement for consumers to know which remote backend served the blob
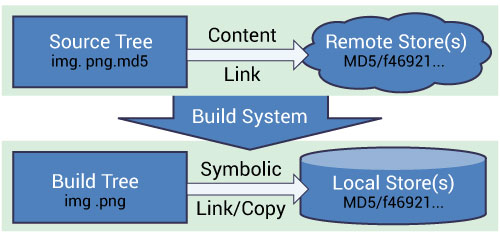
reference: kitware
One pragmatic deviation exists on Windows. Stock ExternalData.cmake copies
objects into ExternalData_BINARY_ROOT, which reintroduces a full build-local
copy before the final build tree.
This repository therefore vendors a small ExternalData patch by default that
materializes directly from the shared object store into the final build tree
and prefers hardlink, then symlink, then copy on Windows.
The patch is kept isolated and general-purpose on purpose so it can be
proposed upstream to Kitware as a normal ExternalData improvement. Consumers
can still fall back to the host CMake module with
-DNAM_USE_VENDORED_EXTERNALDATA=OFF.
The upstream merge request is cmake/cmake!11814.
The first backend is GitHub Release assets.
GitHub release assets documentation:
We don't limit the total size of the binary files in the release or the bandwidth used to deliver them. However, each individual file must be smaller than 2 GiB.
The backend itself does not matter:
- it can be
GitHub Release assets - it can be
S3 - it can be
Nextcloud/WebDAV - it can be
Proxmox Backup Server - it can be a custom object store
- it can be an internal mirror or a static file server
Multiple backends can coexist with ordered fallback. If we later replace GitHub Release assets with a different backend, consumers do not have to notice. They continue to resolve the same manifests into the same logical local files.