Prepare any codebase for AI. Wires OpenCode, OpenSpec, codegraph, and basic-memory into a multi-agent development workflow powered by native parallel subagents.
GitHub, Azure DevOps, Jira, GitLab, browser-based backlog, or combinations (e.g. Jira backlog + GitHub repo, Others (Browser) + GitLab repo).




{kind=link}
{kind=link}
Most codebases have no AGENTS.md, no architecture docs agents can read, and no defined workflow for picking up tasks. Agents end up improvising, producing inconsistent results.
opencode-onboard fixes that in a single interactive wizard. It configures OpenCode with OpenSpec for structured change management, native subagent waves for parallel agent execution, codegraph for code intelligence, and basic-memory for shared context across agent sessions. It also installs an agent team, platform skills, and slash commands — everything agents need to plan, implement, and ship.
npx opencode-onboard@latestRequires Node.js 18+.
You can run individual setup/maintenance steps without running the full wizard:
# Run one step directly
npx opencode-onboard clean
npx opencode-onboard platform
npx opencode-onboard copy
npx opencode-onboard openspec
npx opencode-onboard models
npx opencode-onboard optimization
npx opencode-onboard browser
npx opencode-onboard metadata
npx opencode-onboard join
# Show CLI help and all commands
npx opencode-onboard --help
npx opencode-onboard -hWhen available, step commands reuse context from .opencode/opencode-onboard.json.
Typical flow for reruns:
- Run
cleanif you want to reset old AI files - Run
copyif templates/skills changed in a new onboard release - Run
optimizationif you want to reconfigure RTK/quota/caveman and the AGENTS.md optimization markers - Run
metadatalast to refresh.opencode/opencode-onboard.json - Run
joinif you're a new member of an existing onboarded project and want to sync the latest onboarding metadata
The CLI runs a 10-step onboarding wizard. It keeps the current step visible, plus the last two completed steps, so progress is always clear.
| Step | What happens |
|---|---|
| 1. Source scope | Choose current repo or sibling source roots for code analysis |
| 2. Clean AI files | Detects existing AGENTS.md, .cursorrules, CLAUDE.md, .agents/ etc. and removes them, preserves your .agents/skills/ |
| 3. Choose platform | Backlog (GitHub / Azure DevOps / Jira / Others (Browser) / None) + repo (GitHub / Azure DevOps / GitLab / None). Supports mixed platforms e.g. browser backlog + GitHub repo, Jira backlog + GitLab repo |
| 4. Check platform CLI | Verifies gh (GitHub) or az + azure-devops (Azure DevOps) or acli (Jira) or glab (GitLab). Skips CLI checks for Others (Browser) or None |
| 5. Copy scaffolding | Copies agents + built-in skills + bootstrap docs, writes source-roots metadata, applies AGENTS bootstrap patching, copies skills-lock.json, then runs npx skills |
| 6. Init OpenSpec | Runs npx @fission-ai/openspec init silently for structured change management |
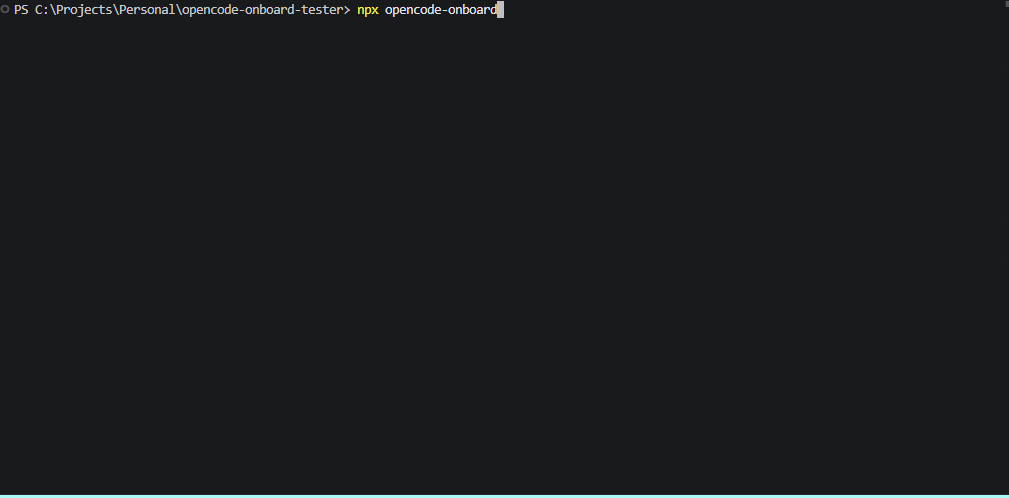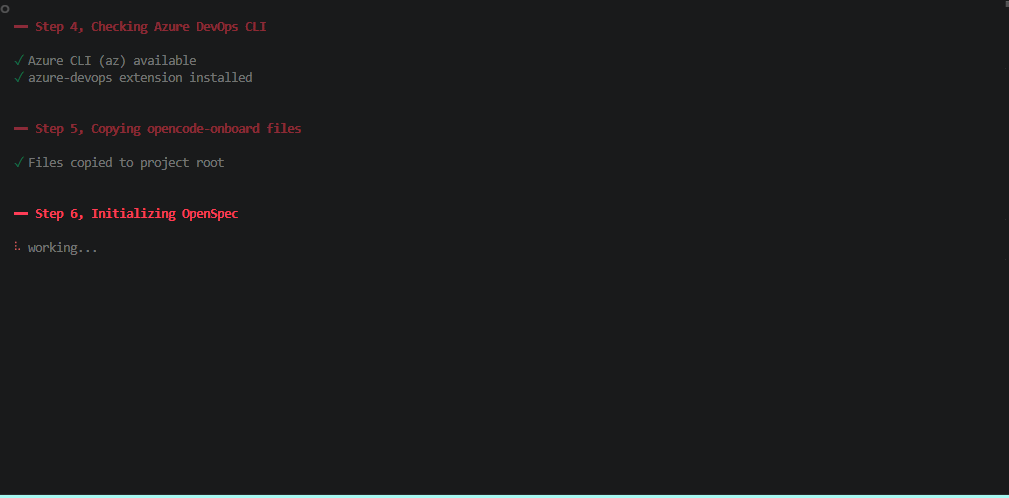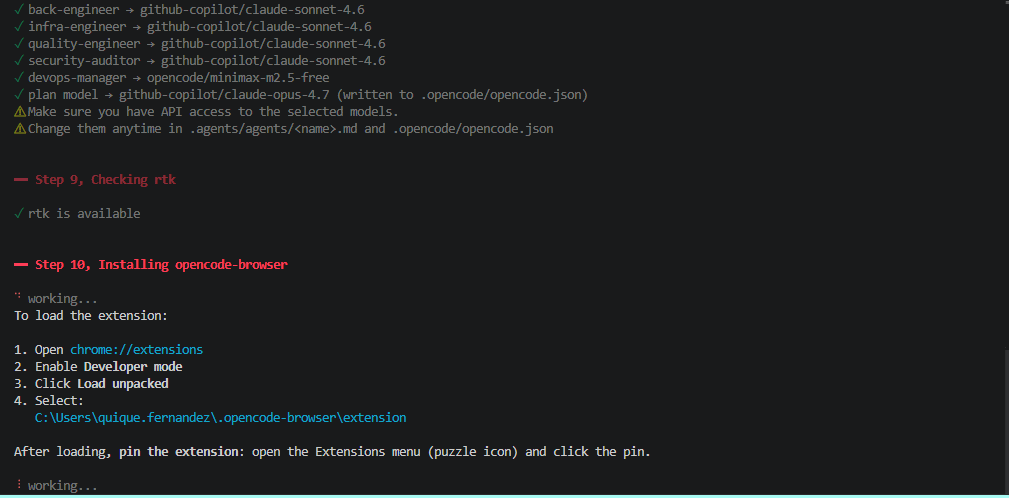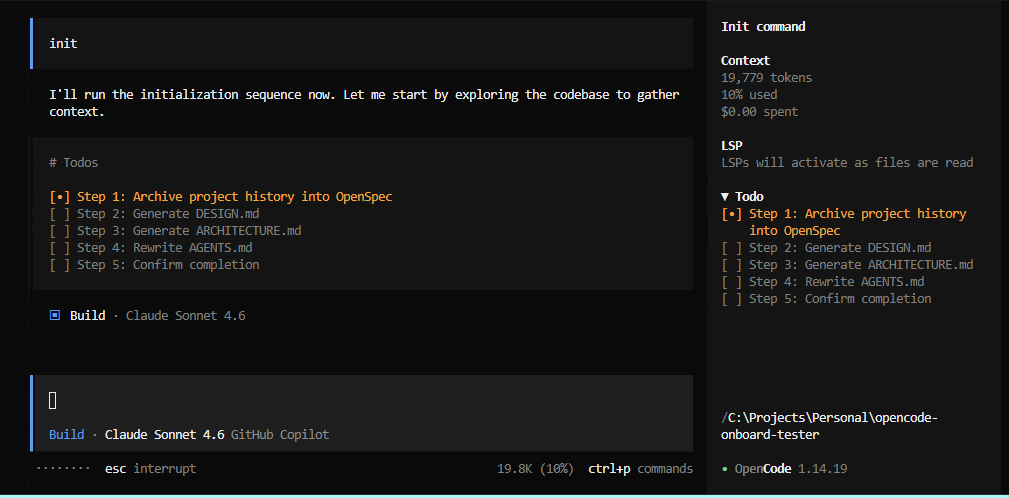
| 7. Choose models | Fetches live model list from models.dev, lets you pick plan / build / fast models with cost indicators and canonical pricing |
| 8. Token optimization tools | Optional (recommended). One checklist step for RTK check, opencode-quota setup, caveman install, and token-optimization rule injection into AGENTS.md + command files |
| 9. Install browser plugin | Installs @different-ai/opencode-browser globally for agent browser automation |
| 10. Write onboarding metadata | Writes .opencode/opencode-onboard.json with selected setup details |
When it finishes, open OpenCode in your project and type:
/ob-init
OpenCode asks if this is a greenfield or brownfield project. For brownfield projects it generates ARCHITECTURE.md and DESIGN.md from your actual codebase, archives project history, then activates the full agent team. For greenfield projects it skips doc generation and leaves placeholder files you can populate later with /ob-create-architecture and /ob-create-design.
Custom slash commands are installed into .opencode/commands/ and are available directly in OpenCode.
| Command | Description |
|---|---|
/ob-help |
Show all commands and when to use each one. Start here if you're unsure. |
/ob-init |
Initialize the project. Asks greenfield vs brownfield, then activates the agent team. |
/ob-explore |
Think through an idea or investigate a problem before committing to a plan. |
/ob-propose <url or idea> |
Parse a GitHub Issue / Azure DevOps / Jira / browser URL or a direct idea into a structured plan (proposal, specs, tasks). Enriches each task with agent and model assignments. |
/ob-apply |
Implement tasks from the current OpenSpec change via parallel subagent waves (native task tool). |
/ob-pullrequest |
Create a PR for the current branch, or read and classify PR review comments. |
/ob-archive |
Archive a completed OpenSpec change. |
/ob-main <task> |
Quick direct implementation — no OpenSpec, no waves, no PR. Just do it. |
/ob-autopilot <feature or URL> |
Autonomous, no-confirmation pipeline: branch off main, then propose → apply → archive (one commit per phase). Default: merge to main + delete branch. Add push keyword to push branch only. Add pr keyword to push + create a PR. For loop-engineering. |
/ob-create-engineer <name> <tier> "<description>" |
Create a custom specialist engineer with skills auto-installed from skills.sh. Agent file is a template; tier variants are injected by the ob-subagent-tiers plugin at startup. |
/ob-create-architecture |
Generate or regenerate ARCHITECTURE.md from the codebase. |
/ob-create-design |
Generate or regenerate DESIGN.md from the design system. |
/ob-create-project-guardrails |
Generate a project-guardrails skill from ARCHITECTURE.md + project config files. Extracts architecture boundaries, naming, code style, testing, and git workflow rules. Updates all *-engineer.md to load the skill. |
/ob-set-model [user] <tier> <model> |
Set the model for a tier (plan, build, fast). Writes to opencode-onboard.json (team) or opencode-onboard.user.json (user override, gitignored) when user prefix is used. Restart to pick up — the ob-subagent-tiers plugin rebuilds tier agents at startup. Pass a model id or current for the active session model. |
opencode-onboard draws a hard line between two concepts:
Agents define how to work. They are universal personas (same behavior across projects and stacks).
Current baseline uses a generic execution model:
lead lead/orchestrator, planning, PR lifecycle
basic-engineer implementation worker, ability-driven
basic-engineer behavior is composed by abilities, not hardcoded role silos.
Project-specific specialization comes from user-created custom engineers via /ob-create-engineer. During /ob-apply, the lead should inspect the engineers that actually exist in .opencode/agents/, prefer matching custom engineers, and fall back to basic-engineer only when no specialist is a clear fit.
Skills define what to know. They provide project rules, platform behavior, and task-specific execution guidance. Agents auto-detect/load relevant skills; you do not manually choose skills per prompt.
If you choose backlog platform None, no userstory skills are injected into the workflow. The project works from direct conversation, local repo context, and optional OpenSpec artifacts only. If you choose repo platform None, no pull-request skills are injected.
Current loading model:
ob-generic-guardrailsis mandatory baseline for every agent (git/secrets/quality rules + the engineer workflow)ob-defaultis fallback when nothing else matches- Baseline context rules and token-optimization guidance live in
AGENTS.md(always in context), not in a skill
Default basic-engineer abilities:
## Abilities
- Guardrails: @ob-generic-guardrails, @ob-default
- Development: @ob-default
- Testing: @ob-default
- Infrastructure: @ob-default
Users are expected to create additional skills and map them into abilities over time.
Built-in skills (ob- prefix) shipped with opencode-onboard:
| Skill | Purpose |
|---|---|
ob-default |
Fallback, when no other skill matches |
ob-generic-guardrails |
Foundation for user guardrails skills |
ob-userstory-gh |
Parse a GitHub Issue URL into a structured work item |
ob-userstory-az |
Parse an Azure DevOps work item URL |
ob-userstory-jira |
Parse a Jira issue URL via acli CLI |
ob-userstory-browser |
Parse work item from any URL via browser automation (Linear, Trello, etc.) |
ob-pullrequest-gh |
Create GitHub PRs with screenshots, triage review feedback |
ob-pullrequest-az |
Create Azure DevOps PRs, triage review feedback |
ob-pullrequest-gl |
Create GitLab merge requests, triage review feedback |
browser-automation |
Browser control via @different-ai/opencode-browser (localhost + browser backlog exception) |
Skills live in .agents/skills/. Any SKILL.md file in a subdirectory is automatically discoverable, write your own and agents will pick them up.
During onboarding you pick three models:
| Role | Used by | Pick |
|---|---|---|
| plan | Main OpenCode session (the lead) | Something capable with strong reasoning |
| build | Specialist engineers (default tier) | Something capable for implementation |
| fast | basic-engineer & light helpers |
Something fast and cheap |
Models are fetched live from models.dev (3000+ models, cached weekly). Cost tiers [$] [$$] [$$$] always reflect the canonical provider price, so github-copilot/claude-opus-4.7 shows [$$] not [$].
When you give the lead agent a work item URL, execution follows this pipeline. If backlog platform is None, skip the work item stage. If repo platform is None, skip the PR stage:
lead
↓
parse work item via userstory skill
↓
openspec-propose
proposal + specs + tasks
↓
[confirm with user]
↓
wave of subagents (basic-engineer / *-engineer, per-tier model)
each implements its assigned tasks → returns result → lead commits group
↓
verify (tests/build/lint as needed)
↓
lead (ship mode, if configured)
commit → push → PR → feedback loop
- Load the platform userstory skill (installed as
ob-userstory, from the variant matching your backlog platform) - Run
/ob-proposeto produceproposal.md, specs, andtasks.md - Confirm with user before implementation
- Run
/ob-applyto orchestrate implementation in waves - Each wave spawns engineers in parallel (
basic-engineerand/or custom engineers, each carrying its own tier model), capped atmaxConcurrentAgents - Each subagent receives its task IDs in its prompt, loads relevant abilities, implements, and returns; the lead commits each group
- Verify with tests/build/lint according to task scope
- Ship/update PR via lead flow
Agents run as native OpenCode subagents in parallel waves — no external plugin, no git worktrees. The lead's Todo pane is the live board, and the ob-subagent-monitor plugin mirrors state to .opencode/.ob-run.json. Navigate into any running subagent with ctrl+x ↓ then ←/→.
your-project/
├── AGENTS.md ← bootstrap mode, replaced after first "/ob-init"
├── ARCHITECTURE.md ← prompt for agents to fill in from your codebase
├── DESIGN.md ← prompt for agents to fill in from your codebase
├── .opencode/
│ ├── opencode.json ← default model + plugin config
│ ├── opencode-onboard.json ← onboarding metadata + runtime config (models, maxConcurrentAgents)
│ ├── agents/ ← basic-engineer + user-created *-engineer files (each carries its model)
│ ├── tui.json ← registers the Subagents sidebar panel
│ ├── tui/
│ │ └── ob-subagents.tsx ← TUI plugin: live Subagents panel in the sidebar
│ └── plugins/
│ └── ob-subagent-monitor.js ← server plugin: writes subagent state → .opencode/.ob-run.json
└── .agents/
└── skills/
├── ob-default/ ← fallback skill
├── ob-generic-guardrails/ ← foundation for user guardrails
├── ob-userstory/ ← the variant matching your backlog platform, renamed on install
├── ob-pullrequest/ ← the variant matching your repo platform, renamed on install
└── browser-automation/
Platform skills ship as suffixed variants (ob-userstory-gh/-az/-jira/-browser, ob-pullrequest-gh/-az/-gl) and the installer copies only the matching one, renamed to its generic name. Source-roots metadata lands in .opencode/source-roots.json; token-optimization guidance is injected into AGENTS.md marker blocks during onboarding.
The first time you type init in OpenCode after onboarding, the agent asks whether this is a greenfield or brownfield project:
- Bootstrap-mode
AGENTS.mdtriggers the initialization workflow - OpenCode archives existing project context into OpenSpec (
project-history) - OpenCode runs
/ob-create-architecture→ generates realARCHITECTURE.mdfrom your codebase - OpenCode runs
/ob-create-design→ generates realDESIGN.mdfrom your design system - OpenSpec
config.yamlis populated with discovered tech stack and domain context - Bootstrap
AGENTS.mdis replaced with production guidance - Team workflows become fully active for normal implementation tasks
- Bootstrap-mode
AGENTS.mdtriggers the initialization workflow - OpenSpec
config.yamlis populated with what is known (intended stack, domain) - Bootstrap
AGENTS.mdis replaced with production guidance ARCHITECTURE.mdandDESIGN.mdare left as placeholder files
Once your codebase has meaningful content, run:
/ob-create-architectureto generate architecture docs/ob-create-designto generate design system docs
Both commands are safe to rerun at any time as the project evolves.
Long unattended agent sessions can consume significant tokens. Set these controls up before first use:
-
Set provider-side limits first — monthly soft-limit + hard usage cap in your provider dashboard:
- OpenAI: platform.openai.com/account/limits
- Anthropic: console.anthropic.com
- Google AI Studio: aistudio.google.com/app/usage
-
Route models by task type — use a fast/cheap model (e.g.
haiku,gpt-4o-mini) for orchestration and status loops; reserve expensive models (e.g.sonnet,opus,gpt-4o) for implementation tasks only. -
Install the quota plugin — the
@slkiser/opencode-quotaplugin adds/quotaand/quota_statuscommands that surface real-time token usage inside OpenCode sessions. -
Use
/quotacheckpoints — run/quotabefore starting any/ob-applysession and after each agent wave. Pause at 75% consumed; stop at 90%. -
Confirm before large runs — the onboarded
/ob-applyworkflow will ask for your confirmation before spawning agents for Medium (4–7 tasks) or High (8+ tasks) scope sessions.
| Requirement | Notes |
|---|---|
| Node.js 18+ | Required |
| OpenCode | The agent runtime |
| gh CLI | GitHub platform, must be authenticated |
| az CLI + azure-devops extension | Azure DevOps platform |
| acli | Jira (Atlassian) backlog platform, must be authenticated |
| glab | GitLab repo platform, must be authenticated |
Wizard choices and defaults live in src/presets/ where possible:
source.jsoncontrols source-scope prompt optionsplatforms.jsoncontrols platform labels, CLI checks, and backlog-only flagsclean.jsoncontrols AI file detection and preservationmodels.jsoncontrols model role prompts and agent assignmentsoptimization.jsoncontrols RTK/quota/caveman checklist defaultsquota.jsoncontrols opencode-quota defaultsbrowser.jsoncontrols opencode-browser installer automation
git clone https://github.com/ckgrafico/opencode-onboard.git
cd opencode-onboard
pnpm install
# Run the CLI locally
node src/index.js
# Run tests
pnpm test
# Run linting
pnpm lint
# Fix auto-fixable lint issues
pnpm lint:fix
# Watch mode
pnpm test:watchTests are written with Vitest. Linting uses ESLint flat config with Node ESM defaults and stricter correctness rules.
MIT © ckgrafico